인덱스란?
- 색인을 통해 데이터를 빠르게 찾을 수 있도록 해줌
- 설정한 키를 기준으로 정렬한 테이블을 인덱스라 하며, where 절을 타야 적용됨
특징
- 항상 최신의 정렬 상태를 유지
- 하나의 데이터베이스 객체
- → 데이터베이스 크기의 약 10% 정도의 저장 공간 필요
인덱스 알고리즘
- Full Table Scan
- 적용 가능한 인덱스가 없는 경우 사용
- 인덱스 처리 범위가 넓은 경우 사용
- 크기가 작은 테이블에 엑세스 하는 경우 사용
- B-Tree(Balanced-Tree)
- 트리 높이가 같음
- 자식 노드를 2개 이상 가질 수 있음

인덱스 종류
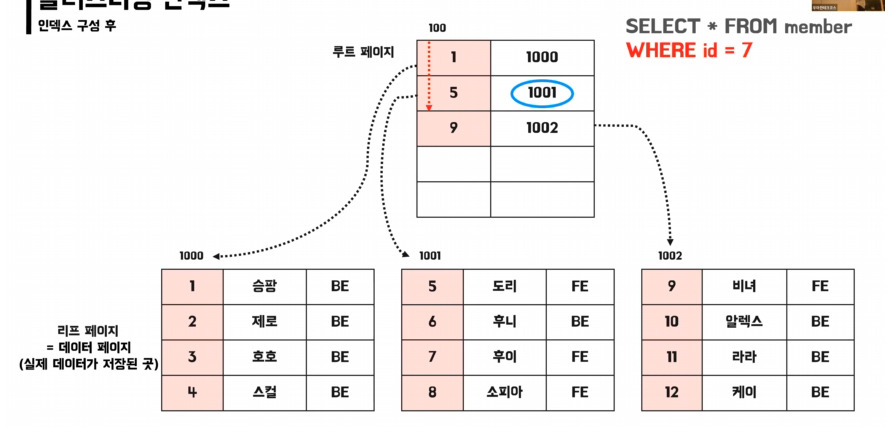
클러스터링 인덱스
- 실제 데이터와 같은 무리의 인덱스ex) primary key
특징
- 실제 데이터 자체가 정렬
- → 테이블당 1개만 존재 가능
- 리프 페이지가 데이터 페이지
- 아래의 제약조건 시 자동 생성
- primary key (우선순위)
- unique + not null
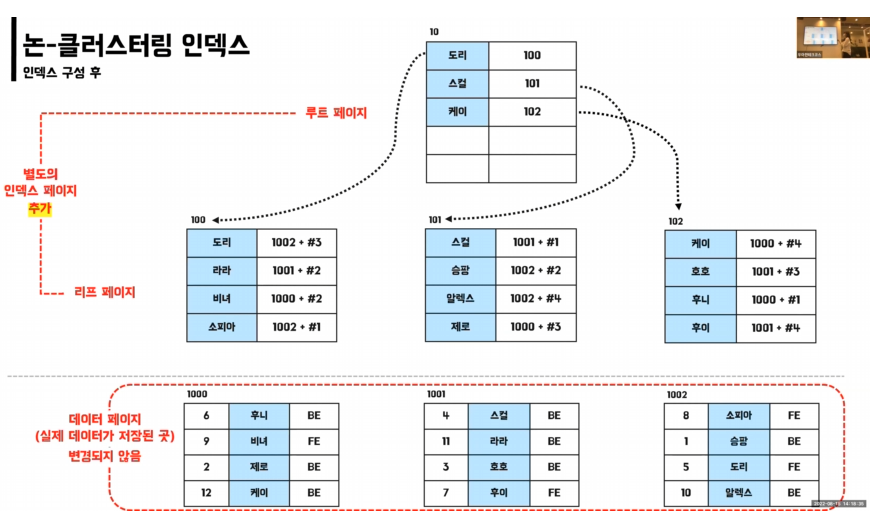
논-클러스터링 인덱스 (보조 인덱스, 세컨더리 인덱스)
- 실제 데이터와 별도의 무리의 인덱스
특징
- 실제 데이터 페이지는 그대로 존재
- 별도의 인덱스 페이지 생성 → 추가 공간 필요
- 테이블당 여러 개 존재 가능
- 리프 페이지에 실제 데이터 페이지 주소를 담고 있음
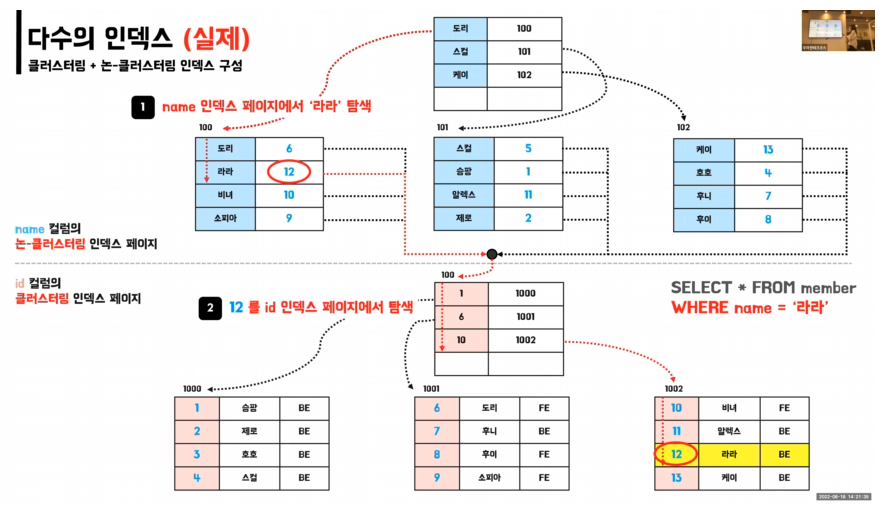
클러스터링 + 논-클러스터링
- 논클러스터링 인덱스에서 실제 주소가 아닌 id를 바라보는 이유
- data 변화 시 클러스터링 인덱스인 원래 데이터에 순서변화가 생길 수있고, 인덱스 테이블 변화가 많아져서
인덱스 선택 기준
- 카디널리티가 높아 중복이 낮은 컬럼
- 카디널리티 : 해당 컬럼 내 요소의 개수 ex)성별은 남여 2개
- where, join, order by 가 자주 사용되는 컬럼
- insert/ update/ delete가 자주 발생하지 않는 컬럼
- 규모가 작지 않은 테이블
[10분 테코톡] 라라, 제로의 데이터베이스 인덱스를 듣고 정리한 내용입니다.